The stochastic gradient descent (SGD) algorithm is one of the most widely used iterative algorithms in optimization theory and machine learning. It gained its fame recently due to the rise in the large number of data samples, which makes it difficult for most computers to solve machine learning problems using traditional gradient descent algorithm.
Like the gradient descent algorithm, SGD is also used to find the minimum of an objective function. The algorithm works by repeatedly taking steps in the direction of the negative gradient of the function, where the gradient measures the rate of change of the function at a given point. Now you may wonder if this has the same working principle as of the gradient descent algorithm. However, there is one subtle change in SGD: “It updates the solution by processing one data sample per algorithmic iteration“.
Note: A different flavor of SGD algorithm also exists, which uses a small batch of samples to update the algorithm and is known as Mini-batch stochastic gradient descent.
In this article, we will introduce the stochastic gradient descent algorithm (SGD) and show its convergence using the MNIST dataset.
Why SGD?
One should ask: “Why do we need SGD? if we already have a gradient descent algorithm?”
Even though gradient descent is a much better choice, when it comes to minimizing the objective function in most machine learning problems as it uses all the data samples available to find the gradient by averaging out (see Unraveling the Gradient Descent Algorithm: A Step-by-Step Guide) and then find the optimal point. However, in most modern and real-world settings, the data is very large and can’t be stored in one computer (requires a lot of memory/storage), which makes gradient descent an infeasible choice for solving machine learning problems. There are other numerous advantages of using the SGD algorithm:
Tackles storage issues by processing one data sample per iteration.
More robust to noise in the data.
Faster convergence than gradient descent algorithm
By providing these advantages, SGD compromises on accuracy when compared to gradient descent.
Mathematical Formulation
The fundamental idea of the stochastic gradient descent algorithm is to find the optimal solution of the following stochastic optimization problem:
Where $f : \R^n \to \R$ is an unknown deterministic function, $F: \R^n \times \Omega \to \R$ is a known stochastic function, $\bxi: \Omega \to \R^d$ is a random variable (this is a random data sample), and $\mathbb{E}[\cdot]$ denotes the expectation operator taking an expectation due to the random variable $\bxi$.
The Algorithm:
Algorithm - Stochastic Gradient Descent (SGD)
Input: A random vector $\bx_0 \in \R^n$ and a decaying step size $\gamma_t > 0$;
1. for $t=1,2,\ldots,$ do
2. $\qquad$ Evaluate the stochastic gradient mapping at $\bx_t$, i.e., evaluate $\nabla F(\bx_t, \xi_t)$;
3. $\qquad$ Do the following update:
$\qquad$ $$ \bx_{t+1} := \cP_{\cX} \left(\bx_t - \gamma_t \nabla F(\bx_t, \xi_t) \right)$$
4. end for
In the above algorithm, $\bx_t$ is the update of the objective variable $\bx$ at time $t$, $\nabla f(\bx_t)$ is the gradient of the loss function $f$, and $\cP_{\cX}$ is the projection operator. We use the projection to ensure that the update of our algorithm doesn’t cause the objective variable $\bx$ to lie outside the feasible set, and if it does, the operator projects the update $\bx_{t+1}$ back to the feasible set. However, in this article, we will use the entire $\R^n$ as our feasible set, so we don’t need a projection operator.
Implementation – The need for an Empirical method
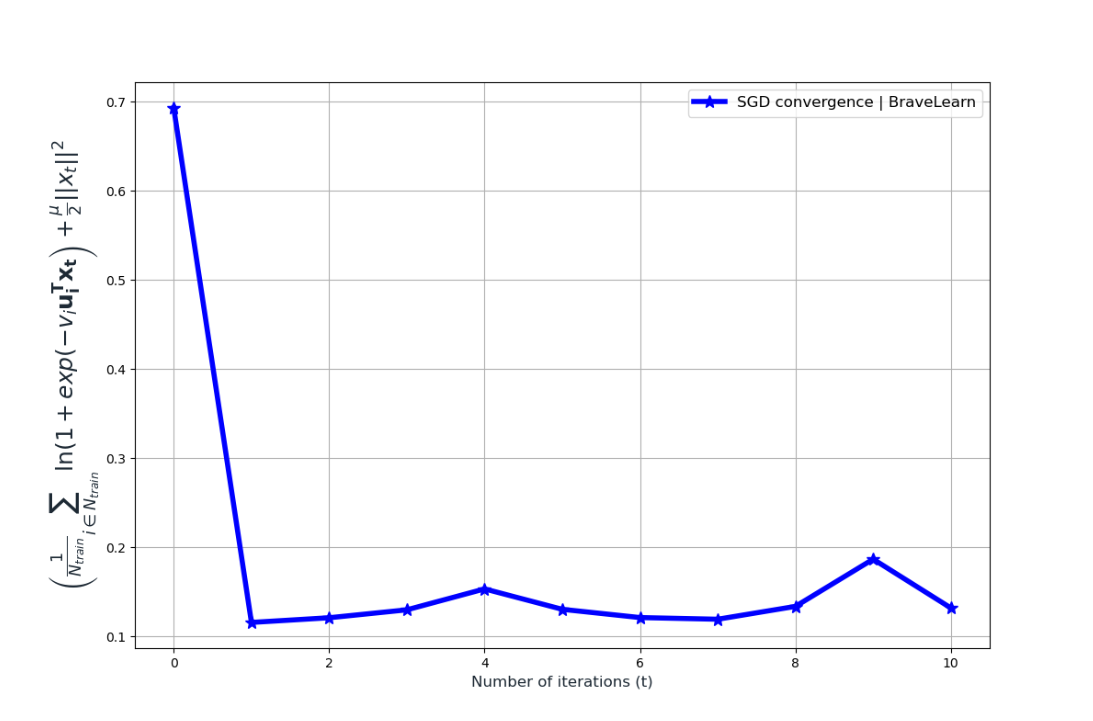
The core idea of this article is to test the performance of the SGD algorithm on real-world data sets like MNIST and see the convergence of the stochastic gradient descent algorithm.
In most machine learning problems, the goal is to minimize the loss function, or more statistically speaking: the expected loss. Mathematically, we define it as:
where $\cL$ is a loss function (can be a logistic loss, a neural network loss function, etc), and $(\bu, \bv)$ is a random input and output variable (input can be a data sample and output can be a class label), and $\bx$ is our optimization variable.
Thought: Why can’t we solve the above problem by using calculus?
Well, in reality, to compute the expectation, we need to know the probabilistic distribution of the data, which is unknown to us, so we have to use empirical methods (hence, the term Empirical Risk Minimization (ERM)). The idea is to collect a large number of data samples and then use averaging to solve the above problem. Hence, we can formulate the above problem as sample averaging approximation (SAA):
Where we denote $N_{train}$ as the total number of data samples (including input and output pair $(u_i, v_i)$) which we will use to find the optimal point for the above problem, this is also called training dataset in machine learning.
The Loss function – Regularized Logistic Regression
To test the convergence of the SGD algorithm on the MNIST dataset, we will use the regularized logistic regression loss function. MNIST data is a classification problem (we have a dataset of handwritten images, and we want to classify the digit of the handwritten image, hence the classification problem), so logistic regression is one of the famous machine learning techniques to solve the classification problem. The loss function is identified as follows:
We will deal with one type of digit (say $3$), i.e., if the input is the image of digit $3$, we will identify the label as $1$ or correct and $-1$ otherwise. Say the input is of handwritten image $4$, then the corresponding label to this image is $-1$. This is why in the above loss function, we are denoting the label’s $v_i$ as a scalar quantity.
Remember in stochastic gradient descent, we don’t have access to all $N_{train}$ data samples.
So, we use the random uniform distribution to draw a random image denoting its index by $j$ and its corresponding label. So, the stochastic gradient update rule by taking the gradient of the above loss function is given as:
Note: In this article, we will implement only a stochastic gradient descent algorithm on the MNIST dataset.
Python Code
Import Libraries:
We need the ‘scikit-learn‘ library to download the MNIST dataset.
import numpy as np
import matplotlib.pyplot as plt
from sklearn.datasets import fetch_openml
np.random.seed(0)
Download MNIST dataset
mnist = fetch_openml('mnist_784', version=1)
mnist.keys()
U0, v0 = mnist["data"], mnist["target"]
U = U0.astype(np.double) # changes the attribute values to float
v = v0.astype(np.uint8) # changes labels from string to integer
Change the labels:
Choose the image $3$ from the MNIST dataset and change its labels to $1$ and $-1$ if the image is not $3$:
v_bin_3 = [2*int(v[i]==3)-1 for i in range(len(v))]
Create a merged data frame of all samples with their corresponding labels
U = np.array(U)
v = np.array(v_bin_3)
df_data_merged = np.concatenate((U, v[:, None]), axis=1)
Define a Split function:
The function below randomly chooses the $N_{train}$ samples from the entire dataset defined by the variable df_data_merged :
Now we define the regularized logistic loss function and its gradient.
## Define the given loss function (which is our regularized logistic loss regression
def loss_f(U_train,v_train,x,N_train):
output = 0
# The loss function is computed for all training images for each x
for i in range(N_train):
vU = np.dot(U_train[:, [i]],v_train[0, i])
vUx = vU.T@x
if (vUx > 709): # to avoid overflow, as python can't handle large numbers
output += vUx
else:
output += np.log(1 + np.exp(-vUx))
return output/N_train + (mu/2) * np.linalg.norm(x) ** 2
## Define the gradient of the objective function for SGD method
# we will process only one image
def stoch_grad_F(U_train,v_train,x, i):
vU = np.dot(U_train[:, [i]],v_train[0, i])
vUx = vU.T@x
# the min function is to avoid overflow, as python can't handle large numbers
output = (mu * x) + ( -vU / (1 + np.exp(min(709, vUx))))
return output
Define the Algorithm for “Stochastic Gradient Method”:
Now, we define the algorithm for the stochastic gradient algorithm; in the following function, we will start with the initial point x_0 and evaluate the loss function at this point (in evaluation, we will use the entire training dataset of N_train samples). We use the concept of the epoch; instead of evaluating the loss function at every update of the algorithm, we perform the update after a certain number of samples which we denote by epoch_length. The rest of the code has comments and is self-explanatory.
def SGD(x_0, T_SGD, stepsize, epoch_length, n_epoch, N_train,U_train,v_train):
f_epoch_vals = np.zeros(n_epoch+1)
# store the initial value of the objective function
f_epoch_vals[0] = loss_f(U_train,v_train,x_0,N_train).item()
x_next = x_0
c=1
for t in range(T_SGD):
x_now = x_next
## generate random sample i (choose randomly any image)
rand_sample = np.random.randint(0, N_train)
x_next = x_now - stepsize * stoch_grad_F(U_train,v_train,x_now, rand_sample)
## evaluate the loss function after every epoch_length iterations
if ((t + 1) % epoch_length) == 0:
f_epoch_vals[c] = loss_f(U_train,v_train,x_next,N_train).item()
c+=1
return f_epoch_vals
Initial Parameters
We have finished the main functions, and now we move to the defining parameters of the code (like stepsize, initial start point, number of training samples $N_{train}$ etc.) so we can call the functions defined above:
N_train = 63000
U_train, v_train = split_train_and_convert(df_data_merged, N_train)
d = U_train.shape[0] # dimension of the data
x_0 = np.zeros((d, 1)) # initial start point
stepsize = 10 ** -6
n_epoch = 10 # It denotes the number of evaluated points in the objective function plot
T_SGD = int(N_train*n_epoch) # Total number of iterations
epoch_length = int(T_SGD/n_epoch) # Number of iterations per epoch
mu = 10 ** -2 # regularizing parameter of loss function
Call the Algorithm
Now we execute the algorithm and store the evaluated values of the loss functions:
Enjoy implementing the stochastic gradient descent algorithm on the MNIST dataset and do experiments with the step size to observe its impact on convergence.
Samplepath Comment: For the SGD algorithm, since randomness is involved, the idea is to run the algorithm multiple times and plot the mean of those multiple runs; however, we skipped this part in the implementation provided above.
This concludes the motivation and implementation of the stochastic gradient descent algorithm; we will provide convergence analysis with convex and non-convex cases of objective functions in the forthcoming articles.